
According to data from Mastercard SpendingPulse, the share of e-commerce in retail sales increased by 13% in 2018. This huge growth of sales has made a massive burst in customer behavior data. Advancements in AI (Artificial intelligence marketing) are giving retailers unprecedented, detailed insights into customer choices and behavior, allowing them to create a better customer experience in a variety of ways: recommending products, personalizing searches, customer support and variable pricing.
Table of contents
Introduction
When we talk about AI, we are actually talking about machine learning, which is a subfield of AI that can teach machine learning and derive insights from input data. This article will introduce two of the most famous machine learning technology classification and clustering, which have had an impact on the field of e-commerce. We will also introduce you to some statistical models that your data scientist might use to help train machines.
Understanding these different models will help you understand the type of technical capabilities you need to have if accuracy is critical to satisfying your customers. Becoming a statistical model expert is not as important as having the technology that can support you. Think of it this way: if you are a bakery and want to provide gluten-free bread, you need to understand every ingredient in the product.
Supervised vs. Unsupervised Learning
Before proceeding with statistical modeling, let us introduce a few terms. Customers want the most relevant results (quality), and this is precision. They also want to choose (quantity), which is called a recall. Therefore, the key is to know how to dance between two things, give them many choices, and then hone the things that are most relevant to them. If you are a buyer, you need to ensure that the data scientist can control the model in order to obtain the highest accuracy. In order to teach the machine which suggestions work and which do not work, we use two methods: supervised learning and unsupervised learning. In supervised learning, we first specify a dynamic target, and then let the machine learn from our data.
For example, suppose we have a bunch of photos or products that contain different fashion items, such as shoes, shirts, dresses, jeans, jackets, etc. We can train a supervised learning model on these photos to learn the items on each photo, and then use the model to identify the same items on the new photos. These items are essentially the target variables that we want the model to learn. In order to perform supervised learning, you must have clearly labeled data. But what if you don’t? Or, what if only some of your data is clearly marked? We eliminate the idea of having target variables, so we call it unsupervised learning. We will further explain the difference between supervised learning and unsupervised learning below.
Importance of Classification in Ecommerce
Wallet or handbag? Sports shoes or sports shoes? Jacket or coat? People call things different things. In retail, the worst thing you can do is to ask search engines to provide customers with any information because they typed alternative words or synonyms. These types of outputs are called discrete output variables, and we use a method called “classification” to train the computer from a series of inputs. Teach the machine to find all the items in a specific class, you need to clearly mark your training data. After cleaning, you can apply several different machine learning algorithms to train the data. Here are some:
1-The k-nearest neighbor (KNN) algorithm is very simple and very effective. Predict new data points by searching for the K most similar instances (neighbors) in the entire training set and summarizing the output variables of these K instances. The biggest use case for k-nearest neighbors is a recommendation system, in which if we know that users like a particular item, we can recommend similar items for them.
In retail, you can use this method to identify key patterns in customer buying behavior, and then predict customer behavior to increase sales and customer satisfaction.
Prediction is performed by “traversing the split part of the tree” until reaching the leaf node and outputting the class value of the leaf node. Decision trees have a wide range of real-world applications, from choosing what to buy to choosing what clothes to wear at an office party.
2 – Logistic Regression is the go-to method when our target variable is categorical with two or more levels.For example, the user’s gender, the result of a sports game, or a person’s political affiliation
3 – Naive Bayes model is contains two types of probabilities, which can be calculated directly from your training data: 1) The probability of each category, and 2) The conditional probability of each category given each value of x. Once calculated, the probabilistic model can be used to make predictions on new data using Bayes’ Theorem
Naive Bayes can be applied to various situations: marking emails as spam or non-spam, predicting sunny or rainy weather, checking customer reviews that indicate positive or negative sentiment, and so on.
Importance of Clustering in Ecommerce
The clustering task is an example of unsupervised learning, which automatically provides clusters of similar things. The main difference with classification is that in classification, we know what we are looking for. This is not the case in clustering. Clustering is sometimes called unsupervised classification because it produces the same results as classification, but there is no predefined class
We can cluster almost anything, and the more similar the items in the cluster, the better our cluster. This concept of similarity depends on similarity measures. Because we have no target variable in the classification, we call it unsupervised learning. Instead of telling the machine to “predict Y for our data X”; we are asking “Can you tell me anything about X?”
For example, we can ask for an unsupervised learning algorithm to tell us about customers purchasing a data set. The content may include: “Based on their zip codes, what are the 20 best geographic regions that we can select from this group of customers? “Or “In this group of customers, the 10 most frequently appearing products?”
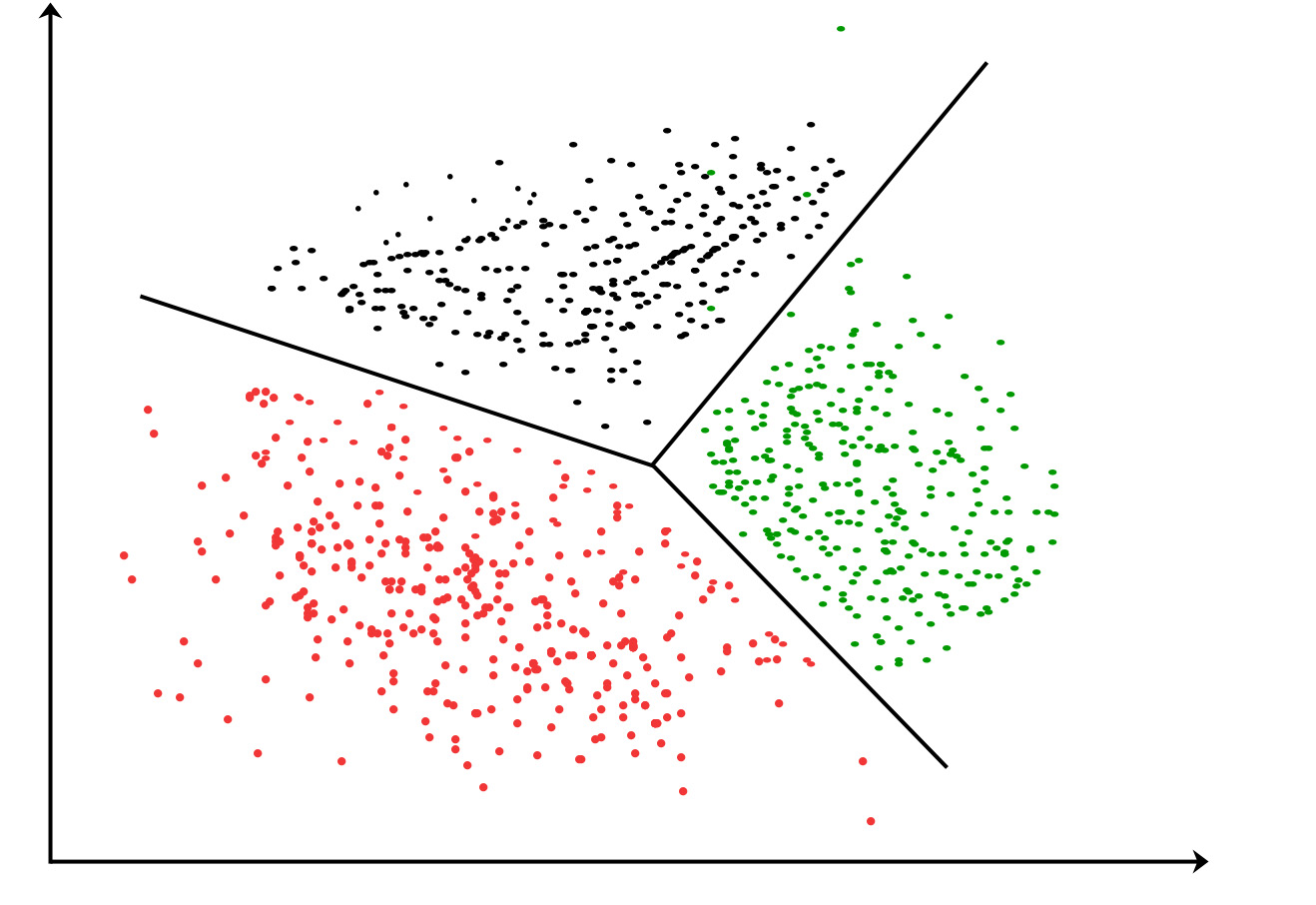
A widely used clustering algorithm is k-means, where k is the number of clusters to be created as specified by the user. The k-means clustering algorithm starts with k random clustering centers called centroids. Next, the algorithm calculates the distance from each point to the cluster center. Every point is associated to the nearest cluster center. Then the cluster center is recalculated based on the new point in the cluster. Repeat this process until the cluster center is no longer moving. This simple algorithm is very effective, but very sensitive to initial cluster placement. In order to provide better clustering, a second algorithm called bisecting k-means can be used. Divide the k-means from all points in a cluster, and then use k-means with k-means to split the cluster. In the next iteration, the cluster with the largest error is selected for splitting. This process is repeated until k clusters are created. Generally speaking, bisecting k-means creates better clusters than the original k-means does.
Conclusion
Supervised learning and unsupervised learning are the two main machine learning methods for most artificial intelligence applications currently deployed in e-commerce technology, each underlying algorithm is the classification of supervised learning and the clustering of unsupervised learning
You can see there is a pretty good amount of tweaking or tuning that could be done to make sure you have that perfect balance of recall and precision. And despite all the math — tuning is more close to art. Access to algorithms in order to continuously improve them is the key.
[yasr_visitor_votes]